What Really Happens When You Run Your Code?
When you hit “run,” your high-level source code (say in Python, Java, or C++) goes on an adventure inside your computer.
The code you write in English-like commands is first translated into something the machine can understand. If your language is compiled, a compiler performs this translation in stages. If it’s interpreted, an interpreter reads and executes your instructions on the fly. In either case, several steps – from lexical analysis (chopping code into meaningful tokens) to parsing (structuring those tokens) to generating machine code – must happen before the CPU actually executes your instructions geeksforgeeks.orgen.wikipedia.org.

Writing code itself usually happens in a text editor or IDE. Beginners often use friendly tools like Visual Studio Code to type and debug code https://code.visualstudio.com/, and may consult step-by-step books such as Python Crash Course https://amzn.to/4jKRMIT or Automate the Boring Stuff with Python https://amzn.to/3Yw6Gdm. These resources are like cooking recipes and kitchen kits for programming – they guide you as you chop up code and cook up programs.
Source Code: The Starting Point
Your program begins as source code – the plain-text file you create (for example, hello.py, Main.java, or program.cpp). It’s written in a high-level language with keywords and syntax that humans can read. But a CPU can’t directly execute this. Think of source code as an English recipe: it needs translation before the chef (CPU) can follow it. Before running, this code is handed off to language-specific tools.
Lexical Analysis: Chopping Code into Tokens
The first real step in compilation is lexical analysis (or “scanning”). The compiler reads your source code character by character and groups them into tokens – the smallest meaningful pieces (keywords, identifiers, numbers, symbols)geeksforgeeks.org. For example, in print(1+2), the lexer would break this into tokens like print, (, 1, +, 2, and ). You can imagine a chef chopping a recipe into ingredients. In code, tokens are like ingredients (keywords, variable names, operators) that a later step will use. The lexer skips whitespace and comments, ensuring the raw text is structured into this token stream geeksforgeeks.org.

Parsing: Building the Syntax Tree
Next comes parsing (syntax analysis). The parser takes the token stream and checks if it follows the language’s grammar. It organizes tokens into a tree structure – often called a parse tree or abstract syntax tree (AST) – that represents the program’s syntactic structure en.wikipedia.org. Continuing our recipe analogy: parsing is like arranging ingredients into the steps of a recipe. For example, it verifies that something like if (x > 0) { … } is a valid structure. If the tokens form a valid program, the parser builds the tree; if not, it reports errors. In effect, parsing ensures the code makes sense according to language rules en.wikipedia.org.

Compiling Your Code: From Source to Machine Instructions
In compiled languages (like C or C++), after parsing the code, the compiler generates machine code. A compiler is a program that “translates” your source into a low-level target (often machine code) en.wikipedia.org. It typically does this in phases en.wikipedia.org:
-
Lexical analysis – breaks code into tokens geeksforgeeks.org.
-
Syntax analysis (parsing) – organizes tokens into a parse/AST en.wikipedia.org.
-
Semantic analysis – checks for meaning (types match, variables declared).
-
Intermediate/optimized code generation – transforms the AST into an intermediate form and optimizes it for speed or size.
-
Machine code generation – finally emits actual machine instructions (object code).
For example, compiling C++ with g++ runs these steps, producing object files and libraries. These object files aren’t runnable yet – they contain raw machine instructions for each source module.
_____________________________________________________________________
The Linker and Loader: Putting It All Together
After the compiler produces object files (machine code pieces), a linker combines them into an executable program en.wikipedia.org. The linker resolves references between modules: say your main.cpp calls a function in utils.cpp, the linker patches those calls together. It also pulls in needed library code. (This is why multiple source files can be compiled separately.) As Wikipedia explains, “a linker…combines object and library files into a single executable file such as a program or library” en.wikipedia.org. Static linking copies needed library code into your executable; dynamic linking arranges to load libraries at runtime.

Once linked, the final loader (part of your operating system) places the executable into memory and prepares to run it en.wikipedia.org. The loader sets up memory (stack, heap) and then jumps to the program’s entry point (often main). Think of this step like placing a completed machine (your program) onto a factory floor (RAM) and turning it on. The CPU is now ready to execute the instructions step by step.
_____________________________________________________________________
Interpreted Languages: Running Code On the Fly
Not all languages go through this ahead-of-time compile-and-link process. Interpreted languages like Python, Ruby, or JavaScript use a different approach. An interpreter is a program that directly executes source code instructions (often after a small translation) without first producing a standalone machine-code binary en.wikipedia.org. In other words, the interpreter acts as a translator-chef in real time. For example, when you run a Python script, the Python runtime compiles the .py source into bytecode (a low-level, platform-independent form) and then executes it with the Python Virtual Machine (PVM) stackoverflow.com.
Other interpreted languages (like classic BASIC or early JavaScript) parse and execute each statement directly. The interpreter might perform steps similar to a compiler’s – it still tokenizes and parses the code – but it executes instructions on the fly. For instance, the Lua or Perl interpreter reads each line, compiles it to an internal form, and runs it immediately. The result is that you never see a .exe file on disk; the code runs as soon as you invoke the interpreter.
_____________________________________________________________________
Bytecode and Virtual Machines:
Some languages use a hybrid model. Java, for example, compiles source to bytecode (an instruction set for the Java Virtual Machine), not directly to your machine’s native code. As Wikipedia notes, “Java bytecode is the instruction set of the JVM, the language to which Java and other JVM-compatible source code
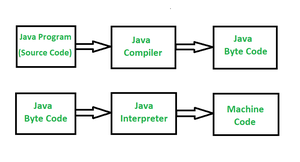
is compiled” en.wikipedia.org. At runtime, the JVM either interprets these bytecode instructions or just-in-time (JIT) compiles them into native machine code en.wikipedia.org. This design gives cross-platform flexibility: the same
.class files run on any OS with a JVM. The JIT compilation combines benefits of both worlds – it translates to fast machine code on the fly, as needed. (C# and .NET work similarly with the Common Language Runtime (CLR).)
In short, whether you say a language is “compiled” or “interpreted” often comes down to its usual implementation. Python and Ruby are typically run by interpreters, while C/C++ are compiled to binaries. Languages like Java or C# use an intermediate bytecode and a runtime engine (JVM or CLR) to execute code.
_____________________________________________________________________
Compiled vs Interpreted: Pros and Cons:
Broadly speaking:
-
Compiled languages -(C, C++, Rust, Go, etc.) transform all source code into machine code ahead of time. You end up with a native binary that the CPU executes directly en.wikipedia.org. This usually makes them fast at runtime, because there’s no translation overhead and the compiler can optimize heavily. (Indeed, native-compiled programs “tend to run faster than if interpreted” en.wikipedia.org.) On the other hand, you lose a bit of flexibility: you must recompile the code for each target platform, and compile times can slow your edit-test cycle.
-
Interpreted languages -(Python, Ruby, JavaScript) are generally slower in raw execution, because the interpreter is working while the program runs. However, they are very flexible for development: you can often write code and run it immediately without a separate compile step. They’re great for scripts, web code, and quick prototyping. As Wikipedia summarizes, an interpreter “executes instructions…without requiring them to have been compiled into machine code” en.wikipedia.org. Modern interpreters mitigate speed issues with techniques like bytecode caching and JIT compilation.
-
Bytecode languages -(Java, C#) aim for a middle ground. The initial compile to bytecode catches syntax errors early and can optimize to some extent. The runtime (JVM/CLR) takes care of portability and often performs JIT optimizations at runtime.
In practice, most languages blur the line. For example, even CPython (the standard Python) will compile .py to .pyc bytecode automatically on first run (and reuse it later) stackoverflow.comstackoverflow.com. Conversely, you can compile many “interpreted” languages (like PHP or Ruby) into bytecode or even machine code with special tools.
_____________________________________________________________________
Runtime Environments: The Context of Execution
No matter how code gets to machine instructions, it runs within a runtime environment – a layer of software that supports the program while it runs. This includes the operating system, runtime libraries, and (for some languages) a virtual machine. In BASIC (an interpreted language), for example, the RUN command was literally a small runtime system that set up the program execution. TechTarget explains: “This is the runtime system. It is its own program that puts a layer
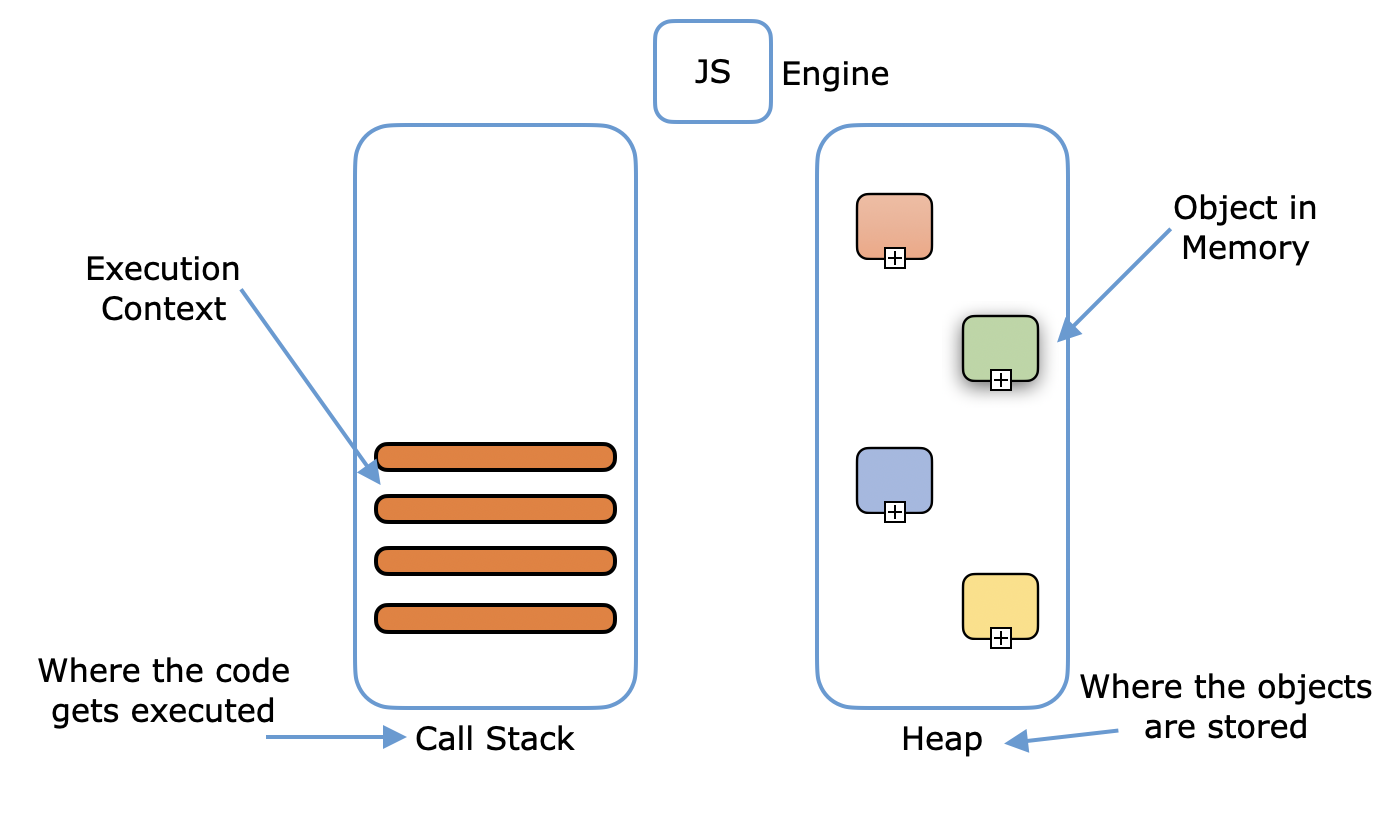
The runtime environment handles tasks such as allocating memory (stack and heap), managing function calls, I/O with devices, and maybe even garbage collection or threads techtarget.comtechtarget.com. In effect, it’s like an on-call team that helps your program: every function call, every variable access, every file operation goes through this layer. When you run your program, the OS gives control to the runtime, which then executes your code instructions in the right context. Errors that occur at runtime (not compile-time) – such as running out of memory – are managed or reported by this environment.
_____________________________________________________________________
Putting It All Together:
Ultimately, running code is a journey: you write a program (source code) → it gets analyzed and translated (by a compiler or interpreter) → an executable form is produced → the OS loads it → the CPU executes it. Each language’s ecosystem handles these steps a little differently, but the core ideas are consistent. Understanding this pipeline can make you a better programmer: you’ll know why a missing semicolon stops compilation, why dynamic languages catch errors later, and how performance optimizations fit in.
For beginners wanting to explore, there are many friendly tools and resources. A good IDE like Visual Studio Code https://code.visualstudio.com/ offers syntax highlighting and debugging to see how code runs. Introductory books such as Python Crash Course https://amzn.to/4iPH02D or Automate the Boring Stuff with Python https://amzn.to/3Z2SubS can guide you through writing your own programs step by step. If you enjoy hands-on learning, consider electronics/coding kits: for example, an Arduino Starter Kit https://amzn.to/4d4ROsx or Raspberry Pi 4 Kit https://amzn.to/4jRxmOj lets you write code that interacts with the physical world (lights, sensors, motors) – great fun and very concrete feedback on your code.
Running code might seem magical, but it’s really a multi-stage process under the hood. Next time you write a program and run it, remember: there’s a whole pipeline at work, from text to tokens to binary to results!



Comments
Post a Comment